

In today’s fast-paced digital world, real-time data is critical for making informed decisions. From e-commerce clickstreams to IoT sensor data, the ability to process and analyze information as it arrives provides a significant competitive advantage. This blog post will demystify AWS Kinesis Data Streams by breaking down its core components and explaining how to build a scalable, end-to-end data pipeline.
For a Non-Technical Audience
“Think of Kinesis as a super-fast data conveyor belt. It’s an Amazon (AWS) service that grabs a constant flow of information—like website clicks, sensor readings, or app activity—and delivers it instantly to be processed. This lets companies react to new data as it happens, rather than waiting hours or even days.”
For a Technical Audience
Kinesis is a scalable, real-time data streaming platform on AWS. It ingests, processes, and analyzes high-volume data streams from various sources. It’s a key service for building real-time applications, enabling immediate insights and responses to new data. Its main benefit is its ability to handle massive data throughput with low latency, which is crucial for applications that require timely analysis and processing.
Architecture Design & Explanation
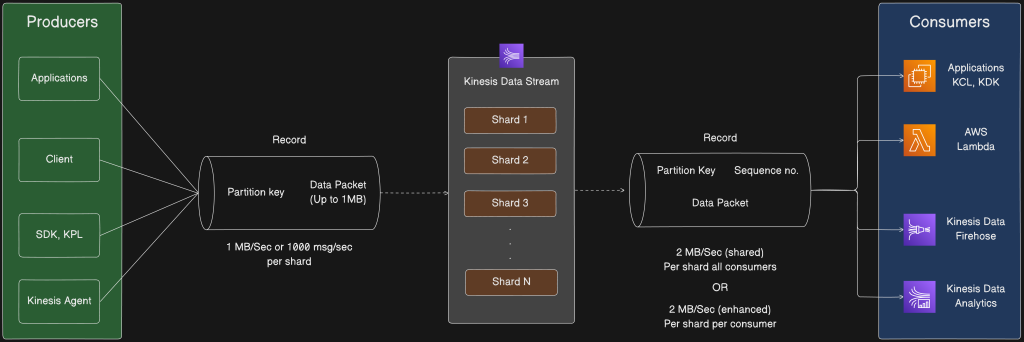
The Core Concept: A High-Speed Data Conveyor Belt
At its heart, a Kinesis Data Stream is a powerful, highly scalable conduit for ingesting and processing data. Imagine it as a continuous, high-speed conveyor belt for data records. Producers place data onto the belt, and consumers retrieve it, all in real time. The stream stores records for up to 365 days, ensuring that consumers can process the data even if they are temporarily offline.
The Producers: Ingesting the Data
On one end of the pipeline are the Producers—the applications and services that send data into the stream. The diagram illustrates several ways to get data into Kinesis:
- Applications and Clients: Your custom applications can directly send data using the AWS SDK.
- Kinesis Producer Library (KPL): For higher throughput and reliability, the KPL is a recommended tool. It handles tasks like batching, compression, and retry logic to efficiently send data.
- Kinesis Agent: This is a stand-alone Java application that continuously monitors log files and sends new data records to your stream.
Every piece of data sent to the stream is called a Record. A record contains two main parts: a Partition Key and the Data Packet itself. The partition key is essential for distributing data across the stream’s processing units.
The Kinesis Data Stream: Shards and Throughput
The heart of the stream is its Shards. A shard is a base throughput unit that provides a fixed capacity for both data input and output.
- Ingestion: Each shard can handle 1 MB/second or 1000 messages/second of data.
- Parallelism: The stream is composed of multiple shards, allowing you to scale the throughput by simply increasing the number of shards. This ensures the stream can handle any volume of data.
- Record Structure: When a record enters the stream, it is assigned a Sequence Number and stored. The sequence number guarantees the order of records within a shard. The Partition Key is used to determine which shard a record is written to, ensuring that records with the same key always end up in the same shard and are processed in order.
The Consumers: Acting on the Data
On the other end of the pipeline are the Consumers—the applications and services that read and process the data from the stream. The architecture supports a wide variety of consumption methods to suit different use cases.
- Applications (KCL / KDK): You can build custom applications to read data from the stream using the Kinesis Client Library (KCL). The KCL handles complex tasks like sharding, record checkpointing, and load balancing across multiple consumer instances.
- AWS Lambda: Kinesis can directly trigger an AWS Lambda function. This is a powerful, serverless way to process data as soon as it arrives without managing any servers.
- Kinesis Data Firehose: If your goal is to simply move data from the stream to a data store, Kinesis Data Firehose is a fully managed solution. It automatically loads data into services like Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service.
- Kinesis Data Analytics: For real-time analysis, Kinesis Data Analytics allows you to process data from the stream using standard SQL or Apache Flink. This enables you to perform time-series analysis, aggregations, and other real-time computations.
The throughput for consumers is 2 MB/sec per shard, which is shared among all consumers. However, an enhanced fan-out option provides each consumer with a dedicated 2 MB/sec per shard, ensuring that a single consumer doesn’t impact the performance of others.
Conclusion: Building a Scalable Data Backbone
The Kinesis Data Streams architecture provides a robust, scalable, and flexible solution for real-time data processing. By understanding the roles of Producers, Shards, and the various Consumers, you can design a pipeline that can handle massive data volumes and power critical business applications. This end-to-end model is a foundational component of any modern data-driven architecture.