

Headline: Why Your Business Needs a Real-Time Data Backbone: A Practical Guide to Apache Kafka
Target Audience: Business leaders, managers, and anyone who needs to understand the “why” behind real-time data processing without getting lost in technical jargon.
Blog Content:
You’ve probably heard the term “real-time data” thrown around in meetings. It’s the idea that your business can react to events as they happen, not hours or days later. But how do you actually achieve this? The secret weapon for many of the world’s most innovative companies is a technology called Apache Kafka.
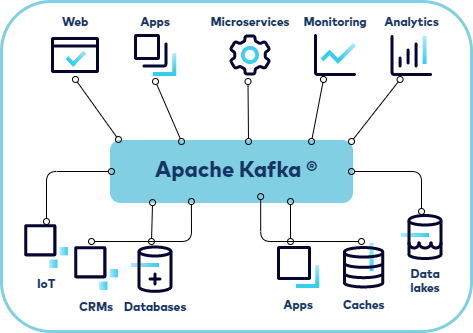
Think of Kafka as a central nervous system for your business data. Every action—a customer clicking a link, a product selling out, a sensor reporting a temperature—is a signal. Kafka is the system that instantly captures these signals and distributes them to all the right applications that need to react.
The Old Way vs. The Kafka Way
Imagine a large e-commerce store before Kafka. The marketing team wants to send a promo email when a customer views a product but doesn’t buy it. The inventory team needs to update stock levels every time an item is sold. The customer support team needs a heads-up when a customer reports a bug.
In this scenario, you’d have to build a custom, one-to-one connection between every single system. It would look like a tangled web of wires, and if one system breaks or you want to add a new feature, you have to untangle the whole mess.
With Kafka, you untangle the mess. All your applications—marketing, inventory, customer support—don’t need to know about each other. They just need to know about Kafka.
- The e-commerce site sends a message to Kafka that says “Product X was viewed.”
- The marketing system reads this message from Kafka and sends the promo email.
- The e-commerce site sends a message to Kafka that says “Product Y was sold.”
- The inventory system reads this message from Kafka and updates its stock count.
A Real-World Example: Uber’s Ride-Hailing Service
Uber’s business model is all about real-time. When a rider requests a car, that’s an event. When a driver accepts the request, that’s another event. When the car’s location updates, that’s yet another event.
Uber uses Kafka to handle all of these events instantly. Every single ride, from the moment it’s requested to the moment it’s completed, generates dozens of messages that flow through Kafka.
- A new ride request is sent to the “ride-requests” topic.
- The driver-matching system reads from this topic to find the closest driver.
- The location tracking system reads from another topic to update the rider’s map.
- The payments system reads from a “ride-completed” topic to process the payment.
This is how Uber can manage millions of rides per day, with each action happening in a fraction of a second. It’s this kind of data backbone that allows a business to operate at a massive scale with precision and speed.